Throughout this page we will use as an example a spreadsheet that stores information about a housing renting system, gathering information about clients, owners and rents. It also stores prices and dates of renting. The name of each column gives a clear idea of the information it represents. The 'totalDays' column is represented by a formulas which subtracting the column 'rentFinish' to 'rentStart'. The 'total rent' column is also represented by a formula that multiplies the total number of days of renting by the rent per day value.

This spreadsheet defines a valid model to represent the information of the renting system. However, it contains redundant information. For example, the displayed data specifies the house renting of two clients (and owners) only, but their names are included 5 times. This kind of redundancy makes the maintenance and update of the spreadsheet complex and error-prone. A mistake is easily made, for example by mistyping a name and thus corrupting the data.
The same information can be stored without redundancy. In fact, in the database community, techniques for database normalization are commonly used to minimize duplication of information and improve data integrity.
Functional Dependencies
Database normalization is based on the detection and exploitation functional dependencies inherent in the data. Can we leverage these database techniques for spreadsheets? Based on the data in our example spreadsheet, the tool discovers the following functional dependencies:
clientNo -> cName
ownerNo -> oName
propertyNo -> pAddress, rentPerDay, ownerNo
clientNo, propertyNo -> rentStart, rentFinish, total rent, totalDays
Functional dependency: We say that a set of attributes B (consequent) is functionally dependent on a set of attributes A (antecedent), if A uniquely determines B (notation: A -> B). For instance, the client number functionally determines his/her name, since no two clients have the same number.
After discovering these dependencies we infer a relational database schema which is optimized to eliminate data redundancy. This schema can then be used, either to store the data in a relational database management system, or to create an improved spreadsheet. The figure bellow presents such an optimized and modular spreadsheet for the example. This new spreadsheet consists of four tables/modules (bold boxes): 'property' (left), 'client' (top middle), 'owner' (bottom middle), 'renting' (right).

The obtained modularity solves two well-known problems in databases, namely the Update Anomalies and the Deletion Anomalies. The former problem occurs when we change information in one tuple but leave the same information unchanged in the others. In our example, this may happen if we change the rent per day of 50 of property number 'pg4' to 60. In the modular spreadsheet that value occurs only once in the property table so that problem will never occur. The latter problem happens when we delete some tuple and we lose other information as a side effect. For example, if we delete row 6 in the original spreadsheet all the information concerning property 'pg36' is eliminated.
Spreadsheet Errors Detection
Having computed the functional dependencies, HaExcel generates spreadsheets that respects such dependencies. For example, a primary key of one table means that there are no two rows in the table containing the same values. In the example, the property table the generated spreadsheet will not allow the user to introduce two properties with the same primary key. If the spreadsheet's user does add a new table row with an existent key, the spreadsheet system will warn him/her that an error has been introduced in the sheet. In order to have this behavior HaExcel also produces additional spreadsheet formulas to validate the uniqueness of primary keys. The figure bellow shows the behavior of a spreadsheet system using the refacted/generated spreadsheet.
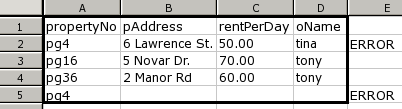
Obviously, it is not possible to perform this validation in the original spreadsheet. The refactoring not only improves modularity and detects the introduction of incorrect data, but also eliminates redundancy: Indeed, the redundancy present in the original spreadsheet has been eliminated. As expected, the names of the two clients (and owners) only occur once.
After establishing a mapping between the original spreadsheet and a relational database schema, we may want to use SQL to query the spreadsheet. Regarding the house renting information, one may want to know who are the clients of the properties that where rented between January, 2000 and January 2002? Such queries are difficult to formulate in the spreadsheet environment. In SQL, the above question can be formulated as follows:
select clientNo from renting where rentStart between '1/01/00' and '1/01/02'
In the paper From Spreadsheets to Relational Databases and Back. we demonstrate that the automatically derived mapping can be exploited to fire such SQL queries at the original or the optimized spreadsheet. We also formalize the correspondence between spreadsheets and relational schemas using data refinement rules. We present formal proofs that guarantee their correctness. The example presented here can be processed by our tool using the online version of HaExcel.
